Easy Introduction to Transformer
記得去年暑假的時候有大概看過 Transformer 是怎麼做的,但那時還太嫩,看了 paper 還是有點霧煞煞,當時網路上其他教學文又都講得有點含糊,多半是放了下面這張圖、擷取論文內容就草草了事,總覺得沒有讀通,後來就放著不管他了。不過幾個月前重新認真讀過 paper 以及後來跟著這篇教學文重新實作,取代成專題中主要的 seq2seq 架構後,算是重新了解了 Transformer。今天就採不同於其他教學文的方式,用實例來讓大家簡單理解 “Attention is all you need” 到底在幹嘛?

Why we need Transformer?
假如今天有個要處理的句子:「潮水退了就知道誰沒穿褲子」總共十二個字(假設 character level 來做),想要做後續的機器翻譯或是任何 NLP 的 task,第一步驟我們會先把它用 embedding 的方式轉成 vector 所組成的 sequence,而這邊的 embedding 可以是簡單的 Word2vec、ELMo、BERT都行,先假設 embedding size 是 512,於是這個句子就變成 12 支 512 維的 vectors。
再來,通常我們會把他丟進去一個 RNN 裡面來處理,像是 LSTM、GRU。這類 RNN 會把句子裡的每個 vector 一個一個的吃進去,在吃的時候記錄下有用的東西在 hidden state 裡面,並且在每個時間點都吐出當下的 hidden state。於是原先的 12 支 512 維的 vectors 經過 RNN 的”閱讀”之後就變成了長度也是 12,但每支 vector 的維度是 hidden size的 vector sequence。
這些 vectors 可能是經過很多層 RNN,或是雙向 LSTM 得到的,取決於你想用什麼架構,都可以,不過在做這些運算的時候都有一個大問題:你要吃第二個字的時候,必須已經吃了第一個字,得到「吃完第一個字之後的 hidden state」,才有資格去吃第二個字,因為第二個 hidden state 需要 depends on 第一個 hidden state!
因為這個特質,原先 DNN 可以透過 GPU 平行化運算來加速的過程,現在又不能加速了,你必須老老實實的從頭到尾算過句子中每一個字,不能同時一起算!這點不像 CNN,雖然你在用 CNN 的時候會以為 convolution 的動作是 filter 們在滑動,好像也很花時間,但其實任何套件實際在算的時候,都是平行化過的,反正 filter 移動到任何一個位置時,都不需要考慮他剛剛在其他旁邊位置時的輸出,所以可以讓 filter 使出影分身之術(?,讓他在不同位置的情況分開且同時算,也就是平行化了。
除了這個問題,RNN 還有一個問題是處理過長的 sequence 時,無法照顧到長距離的 dependency,就算你用 LSTM,如果句子很長,LSTM 吃了數十個字之後,處理到句尾時,句首講的東西可能已經忘光光了,畢竟資訊傳遞的過程太長,不能期望小小的 hidden state 能夠保留著如此多的資訊,況且更可能會有 gradient vanish 的問題。因此,我們想要有一種運算方式滿足以下兩種特質 (1)可以平行化,即處理序列時不會有先後依賴性 (2)長距離的 dependency 之間的 access 不要隔閡太遠。
Why we choose attention?
如果是剛接觸的人,可能會有一種天真的想法,想說如果用一個簡單的 fully-connected feed-forward network,不也可以拿來處理 sequence 嗎?就直接把 12 支 512 維的 vectors 經過 flatten 之後,直接送進去一個 feed-forward network,就可以做後續的事情了,雖然 feed-forward network 看起來不太能吃長度不同的 sequence,但如果把超出 sequence 長度的部分直接放 padding 的 vector 做補滿,設定句子最大長度就好,這樣 network size 就不會不固定了,這樣的話(1)(2)條件都有滿足了,看起來很棒。
But…這會面臨一個更大的基本問題,因為處理 sequence 應該具有平移不變性,當你一個句子從位置 A 開始出現,或是位置 B 才出現,都應該擁有一樣的意思,但因為 feed-forward network 對其每一個維度的處理都是 independent 的,當 sequence shift 一格之後,八成會吐出完全不同的 output,根本上是不可行的,所以我們必須放棄這種天真的想法。
那麼,還有什麼運算方式既能夠滿足(1)(2)條件又不破壞平移不變性呢?就是近年來很常用的 Attention 運算,另外又搭配了許多小 trick,才搭建成了 Transformer 的模型架構。接下來就直接讓我們看一個例子,讓你用人腦 go through 一遍 Transformer 處理文字的歷程。
How Transformer works?
Positional Encoding
沿用剛剛的句子「潮水退了就知道誰沒穿褲子」,經過 embedding 轉成 12 支 512 維的 vectors 後,第一關會經過一個 positional encoding,為何要有這一步呢?因為在之後的所有運算之中,因為是只有作很多 attention,文字的先後順序位置不會影響運算過程!!也因此如果沒有做這步 positional encoding 的話,把一個句子打亂,丟進去 Transformer,所得到的結果會一模一樣!所以這步很重要,model 必須憑藉這外加上去的小小的值,來作為判斷 sequence 中每個 element 之間相對位置的依據。
(其實這招在 ConvS2S 就已經有用了,但不是用 sine/cosine ,而是 learn 出來的 positional encoding)
https://arxiv.org/abs/1705.03122
那 Positional Encoding 實際上到底在做什麼?簡單說就是把這 12 支 512 維的 vectors 的每一維都疊加上一個 sine/cosine function,而每個維度所疊加的 sine/cosine function 週期是不同的。假如你是第k個位置的 vector 的偶數維($=2i$)的數值,你就加上一個 $sin(k/10000^{2i/d_{model}})$ 的小數值,假如是第k個位置的 vector 的奇數維($=2i+1$)的數值,就加上一個 $cos(k/10000^{2i/d_{model}})$ 的小數值,其中$d_{model}$是 embedding 的 vector size,如上面例子就是 512。
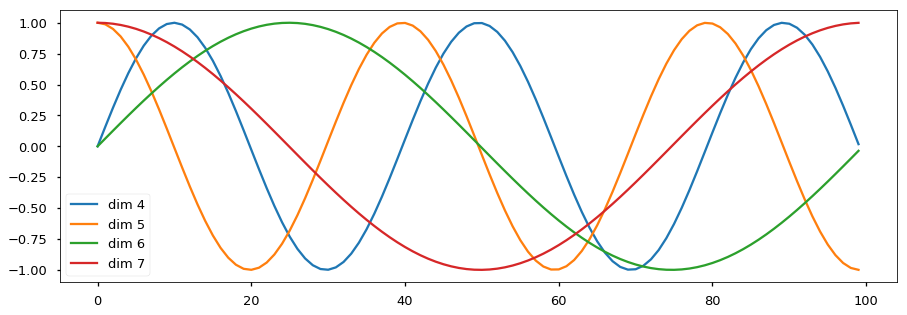
- source: http://nlp.seas.harvard.edu/images/the-annotated-transformer_49_0.png
- 其實在做 positional encoding 之前會把 word embedding vector 都除以 $\sqrt{d_{model}}$。
Encoder Layer
接下來進入主菜,經過 positional encoding 之後,我們仍然要處理 12 支 512 維的 vectors,這時第一步先做 Multi-Head Attention,接著做 Position-wise Feed-Forward Networks。 在進入 Multi-Head Attention 之前會先做一個 Layer Normalization,不知道 Layer Normalization 的可以看這個 BatchNorm 與 LayerNorm 的比較(source):
| BatchNorm | LayerNorm |
|---|---|
| input $x$ (N x D) | input $x$ (N x D) |
| Compute $\mu, \sigma$ of layer | Compute $\mu, \sigma$ of batch |
| $\mu, \sigma$ (1 x D) | $\mu, \sigma$ (N x 1) |
| Params | |
| $\gamma, \beta$ (1 x D) | $\gamma, \beta$ (1 x D) |
| Output | |
| $\gamma*\frac{(x-\mu)}{\sigma}+\beta$ | $\gamma*\frac{(x-\mu)}{\sigma}+\beta$ |
Multi-Head Attention
不管是什麼模型,在做 Attention 的時候,都會有三類向量:V、Q、K。
V 就是 value,也就是資訊所儲存在的向量們,假如你有 12 支向量,裡面有些資訊有用,有些資訊沒用,做 Attention 就會把這些向量依重要性來做加權平均,得到一個代表你需要的資訊的向量。
那麼,這些做加權平均所需要的權重是怎麼來的呢?就是由 K、Q 運算而來,Q 是 query,是當下所需要的處理的字,K
就是每一個 value 都會有一個對應的 key,提供 Q 來做匹配找查的 vector,我們會用 K、Q 經過某些運算,像是內積,或是拿去通過一個 NN,來得到權重值。
在 NLP task 中,常常 V、Q、K 是丟一樣的東西進去,也就是$V=Q=K=[x_1, x_2, …, x_n]$,x 可以是 input 的文字序列(12 支 512 維的 vectors,經過 LayerNorm 之後維度不變)。
在 Multi-Head Attention 裡,進入 attention 運算之前,又有一個小 trick,我們把每一個 input 都分別過 h 個linear projection,從原維度投影到$\frac{原維度}{h}$,在原始設定裡面是h=8,所以 512 維的 input 被投影成 8 個 64 維的 vector,我們對 V、Q、K 都會做一樣的操作,因此最後 V、Q、K 就會被分裂成 8組,每一組裡面分別再各自去做後續的 attention,所以會有 8 個 head 分別去做 attention,這也就是 Multi-Head Attention 名字的由來,這 8 組 head 做完 attention 之後會得到 8 個 64 維的 vectors,最後再 concatenate 起來過一個 Linear,又可以還原回去 12 支 512 維的 vectors了!如下圖:

過完 linear projection 之後要做的 attention 為最簡單的 dot-product attention,但因為有scale by $\sqrt{d_k}$,所以稱為 Scaled Dot-Product Attention:
這裡$QK^T$矩陣乘出來的一個 q×k 維的矩陣,其實就是讓每個 K 去跟每個 Q 相內積,矩陣的第 i,j 項就是第 i 個 Q vector 與第 j 個 K vector 所算出來的權重分數,要 scale by $\sqrt{d_k}$ 的原因是等一下會取 softmax,如果 embedding size($d_k$) 很大,就會有某些 K 跟 Q 相內積的值很大,這樣去取 softmax 之後太過 sharp,會造成 gradient 被壓小,因此 scale by $\sqrt{d_k}$ 會比較合理。
過完 softmax 之後再跟原本的 V 做矩陣乘法,所得到的其實就是 weighted sum,所以最後做完出來就會得到跟 Q 數量一樣多的向量,最後把這些向量過一個共用的 linear projection 就做完了!

過程如這張圖,但其中的 mask 是 decode 的時候才會用到的,現在先不用管他。
做完這些運算之後,我們仍然得到 12 支 512 維的 vectors!!
而在進入下一關之前,會先做一下 dropout,最後也弄一下 residual connection,所以當 encoder layer 最初的輸入為 x 時,最後的輸出會是
x + Dropout(MultiHeadAttention(LayerNorm(x)))。
Position-wise Feed-Forward Networks
接下來要做的是 position-wise feed-forward network,注意這裡的 feed-forward 都是針對每一個”字”經過 attetion 的 vector 所獨立分開做的,而且都共用 network,所以並不是文章一開始提的 naive 的 fully-connected 的方式,也不會有句子最大長度的問題。
跟前面 Multi Head Attention 一樣會先做一個 Layer Normalization,才去做 Feed-Forward,最後再做一個 dropout 跟 residual connection。
而 Feed-Forward 其實沒什麼學問,就直接把每個 vector 都過兩個簡單NN,FC_1 是從 $d_{model}=512$ 映射到 $d_{ff}=2048$,FC_2 是從 $d_{ff}=2048$ 映射回 $d_{model}=512$,全部就是 x -> FC_1 -> ReLU -> Dropout -> FC_2 -> output。做完這些運算之後,我們仍然得到 12 支 512 維的 vectors!
加上頭跟尾的運算,最後的輸出會是
x + Dropout(FeedForward(LayerNorm(x)))。
Encoder
上面講的是一個 encoder layer 所做的事情,實際上會接 N 個 encoder layer 才變成 Encoder, 原始設定是 N=6,而最後 encoder 輸出前會再做一次 Layer Normalization,我們的 Encoder 就這樣大功告成了。注意最後的輸出仍然是 12 支 vectors,這點跟 LSTM 運算會得到的 output 性質是一樣的!唯一不同的是最後有做 Layer Normalization,所以如果你不是要把它拿來做 Seq2Seq 的 task,最後可能要把這部分拿掉,不然就是要確定後面有在接其他 network 做別的 transform 喔!

Decoder Layer
Decoder Layer 基本上跟 Encoder Layer 大同小異,但仍有幾個地方不同:
- 因為 decode 的時候不僅要看當前已生成的句子,也要看 encoder 所給的 memory,所以 Decoder Layer 把這兩件事情分開做。
- Decoder Layer 的第一層是跟 Encoder Layer 的 Multi Head Attention 一樣的東西(除了有 mask 的狀況等等會講,這裡只考慮純 decode 沒有 teacher forcing 的狀況),吃的 input 就是從
<bos>token 開始的生成到一半的句子。
舉例:假如你想要把「潮水退了就知道誰沒穿褲子」翻譯成 “After all, you only find out who is swimming naked when the tide goes out.”,最初你的 Decoder Layer 的第一層吃的 input 就是<bos>一個字而已,因為 input 只有一個 vector ,所以 output 也只會有一個 vector,假如 model 成功的吐出After,這時你再把<bos>、After當成句子丟進去 Decoder Layer 的第一層 input,期望 output 的兩個 vector 會是After、all,以此類推…。 - Decoder Layer 的第二層是跟 Encoder Layer 的 Multi Head Attention 一樣,但是吃的 input 不再是 Q=K=V,而是 Q 放的是目前生成到一半的句子,如上述的
<bos>、After,K=V 放的才是encoder 所給的 memory (也就是剛剛 encoder 最後所吐出來的 12 支 512 維的 vectors),如此一來 model 才能針對 decode 當下所需要吐出的 output 選取他需要的資訊。 - Decoder Layer 的第三層就是 Encoder Layer 的 Position-wise Feed-Forward Networks 完全一樣。
- Decoder Layer 的第一層是跟 Encoder Layer 的 Multi Head Attention 一樣的東西(除了有 mask 的狀況等等會講,這裡只考慮純 decode 沒有 teacher forcing 的狀況),吃的 input 就是從
-
因為在 training 的時候我們會偷偷用 teacher forcing,也就是 input 直接放
<bos>、After、all、…、goes、out、.,output 的目標放的是 input shift 一個位置,拿掉<bos>,加上<eos>的序列,After、all、…、out、.、<eos>。如下例子:Input <bos>After… goesout.Output Afterall… out.<eos>這樣訓練會比較快,而且在訓練初期的時候如果沒有用 teacher forcing 就讓他純 decode 的話通常會壞掉,死得很慘。然而,用LSTM的時候這樣完全沒問題,因爲是單向的,model 在 output第二個字的時候只看到第一個字,但 Transformer 是 input 任意位置都隨便你看,如果沒有預防他偷看下一個字,那他就會直接把右邊的字當成當前位置要輸出的字,這種行為非常母湯,因為真正 testing 時是要純 decode 使用的,那時候就沒得偷看了。所以在用 teacher forcing 的時候我們要用 mask 來防止作弊(也就是剛剛在介紹 Scaled Dot-Product Attention 那邊被我們忽略的東西),在做每一次 attention 的時候,每個位置算出來的 weight 如果是可以讓他偷看到後面的字的 weight,我們就把他 mask 成 zero,如下圖(紫色是被 mask 掉的區域,黃色則是合法區域,橫軸縱軸都是句子長度)。

Decoder
除了上述兩個地方,Decoder Layer 大致上是跟 Encoder Layer 很像的,所以由上面的 1. 告訴我們 Decoder Layer 應該會比 Encoder Layer 多加一層在第二層,然後 2. 告訴我們如果要 teacher forcing,會在第一層執行 mask,第三層 Position-wise Feed-Forward Networks 沒有改變。所以 Decoder Layer 就是長得下面的樣子。

最後,把 Decoder Layer 重複疊 N 次,輸出前再做一次 Layer Normalization 就是完整的 Decoder 了。
最後輸出的向量通過一個簡單的大 Linear,把 512 維投影成 vocab_size 那麼大的 vector(e.g. 10萬之類的),再做最後的 Softmax 就行了,output 的目標就是正確答案。舉例:如果是 teacher forcing,上面那句 17 個字的英文,就把句尾加上 <eos> 就是正確答案。
Other tricks
以上就是整個 Transformer 的架構,但其實 “Attention is all you need” 裡面還有許多讓他達成 state-of-the-art 的 tricks,像是 warm up optimizer、label smoothing 等等,這些就日後有空再介紹了。
待續…
Reference
- Attention is All You Need: https://arxiv.org/abs/1706.03762
- The Annotated Transformer: http://nlp.seas.harvard.edu/2018/04/03/attention.html