RoBERTa: A Robustly Optimized BERT Pretraining Approach
TL;DR
在 BERT 的訓練找到更好的 setting,主要改良:
- Training 久一點; Batch size大一點; data多一點(但其實不是主因)
- 把 next sentence prediction 移除掉
(註:與其說是要把 next sentence prediction (NSP) 移除掉,不如說是因為你會有 50% 的時間在 BERT 的 input 放上不相干的句子,是這件事影響了 performance,但若是在都已經有放不相干句子的情況下,有做 NSP 還是比較好的。BERT 的原作者沒有發現 NSP 無用的原因就可能是因為他們在做 ablation 時還是放了不相干句子,所以誤以為做NSP會比較好)
- sequence 長度要長
- 每次 mask 位置要重新 sample
RoBERTa 在 SQuAD, GLUE, RACE 都拿下 single model 的 state-of-the-art (唯SQuAD2.0拿第二名,差一小點)。
Slide:
Please wait a minute for the embedded frame to be displayed. Reading it on a computer screen is better.
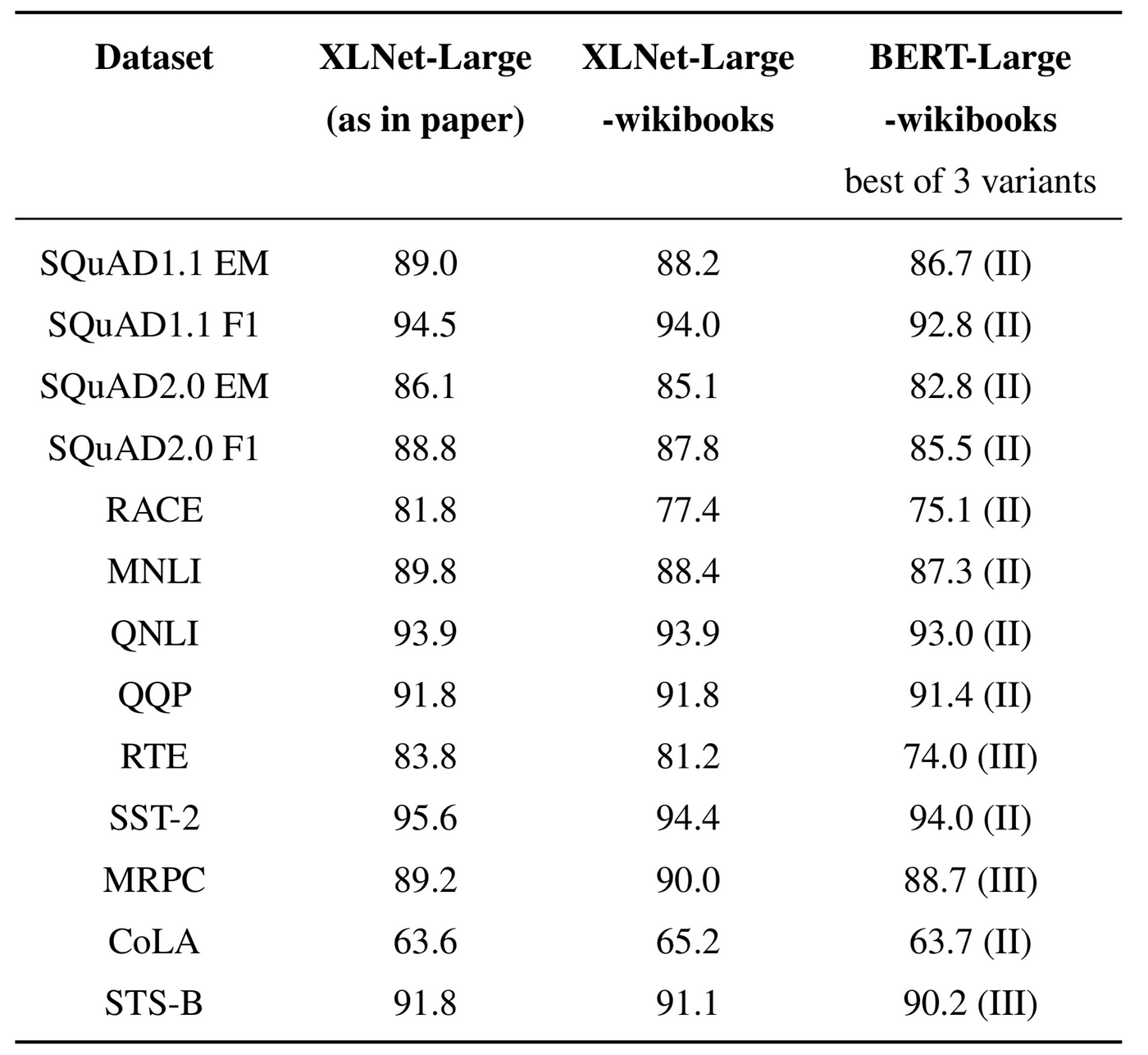
但其實這篇實質上並沒有打敗XLNet,是在 training time 多很多的時候才贏得了,如下表比較:

但大家都似乎以為 XLNet 能夠贏過 BERT 是因為 dataset 大小是 BERT 原做的十倍大,故 XLNet 原作者發了這篇文打臉大家:
A Fair Comparison Study of XLNet and BERT with Large Models https://medium.com/@xlnet.team/a-fair-comparison-study-of-xlnet-and-bert-with-large-models-5a4257f59dc0